Writing type-safe Spark transformations
- 4 minutes read - 674 wordsThere are several options to write type-safe transformations in Scala for Spark. Let’s have a closer look at these.
Sample data set
This record is used in the examples:
case class Rec(id: Long,
name: String,
age: Int,
active: Boolean,
salary: Option[BigDecimal])
Processing
The sample pipeline is to
- filter on an attribute
- select some attributes (projection)
- transform an attribute
The projection’s result is stored in another case class:
case class PartialRec(id: Long,
name: String)
Using the Dataset API
The Dataset API is part of the core Spark functionality.
Given a Dataset like this
val ds: Dataset[Rec] = ???
only type-safe transformations are possible:
val relevantDs: Dataset[PartialRec] = ds
.filter(_.active)
.map(r => PartialRec(r.id, r.name))
val transformedDs: Dataset[PartialRec] = relevantDs
.map(r => r.copy(name = r.name.toUpperCase))
transformedDs.foreach { r =>
println(s"Record: ID=${r.id}, name=${r.name}")
}
The Scala compiler will reject any source in case of an invalid attribute name.
So far so good. But this approach has some problems:
- The data is always fully materialized. This means that all attributes will be read, even if we are only interested in some of these. Imagine a records with lots of attributes, often the result when connecting to legacy source system. On the other hand when you use the DataFrame API, it’s possible to select only the relevant attributes.
- There is no predicate pushdown. This means that the filter is applied after the materialization. For example there is predicate pushdown using Parquet files when using the DataFrame API. This means that the filter is applied while reading, and only relevant records will be returned
As a consequence I have rewritten a lot of code from Dataset API to the DataFrame API for performance reasons. However the DataFrame API does not offer type-safety.
Excursion: DataFrame API
This is how the same transformation would look like when the DataFrame API is used:
val df: DataFrame = ???
val relevantDf = df
.select($"id", $"name")
.where($"active")
val transformedDf = relevantDf
.withColumn("name", upper($"name"))
transformedDf.show(truncate = false)
This is faster, because of the projection using select() and the predicate push down using where(). Both minimizes I/O.
Unfortunately typos in attribute names will not be detected by the Scala compiler.
To mitigate this situation a good integration test coverage (including branch coverage in case of dynamic filtering for example) is required.
Another option is to use constants:
object Db {
object Rec {
val id = $"id"
val name = $"name"
val active = $"active"
}
}
val relevantDf = df
.select(Db.Rec.id, Db.Rec.name)
.where(Db.Rec.active)
This prevents typos in the column names, and it helps in case you have to refactor your data model, so it’s an improvement, but it’s not type-safe.
Alternative 1: Frameless
As an alternative you can use Frameless:
val ds: Dataset[Rec] = ???
val tds: TypedDataset[Rec] = ds.typed
val relevantTds = tds
.filter(tds('active) === true)
.project[PartialRec]
val transformedTds: TypedDataset[PartialRec] = relevantTds
.withColumnReplaced('name, upper(relevantTds('name)))
transformedTds.show().run()
val resultDs: Dataset[PartialRec] = transformedTds.dataset
resultDs.show(truncate = false)
Now if there is a typo in the name of an attribute, the compiler will respond with:
No column Symbol with shapeless.tag.Tagged[String("namex")]
of type A in com.rhaag.spark.notebook.demo.typesafe.Rec
.select(tds('id), tds('namex))
So far, so good.
However there is new problem: Look at the way IDEA is showing the correct source:
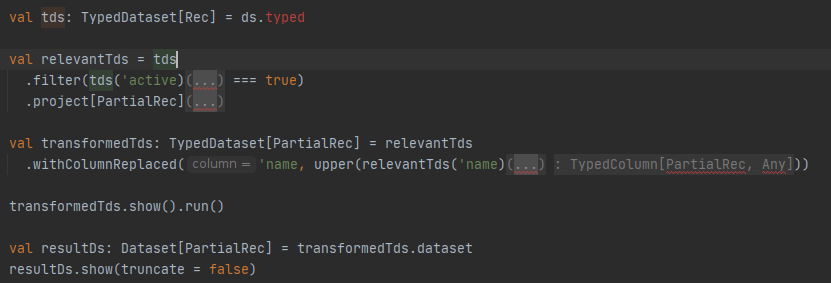
There is a little bit too much of Type-Level magic, and IDEA cannot show it properly.
For this reason in one of my projects we did not opt for Frameless.
Alternative 2: Quill
Quill is another alternative:
val ds: Dataset[Rec] = ???
val transformedDs: Dataset[PartialRec] =
io.getquill.QuillSparkContext.run {
liftQuery(ds)
.filter(_.active)
.map(r => PartialRec(r.id, r.name.toUpperCase))
}
transformedDs.show(truncate = false)
This looks promising. No display issues in IDEA.
Please note that I have not used the copy() method provided by case classes, because this does not work:
val resultDs: Dataset[PartialRec] =
io.getquill.QuillSparkContext.run {
liftQuery(ds)
.filter(_.active)
.map(r => PartialRec(r.id, r.name))
.map(r => r.copy(name = r.name.toUpperCase))
}
It fails with an error message:
Tree 'r.copy(x$25, x$24)' can't be parsed to 'Ast'
.map(r => r.copy(name = r.name.toUpperCase))
This might be cumbersome in case there are lots of attributes, all required, but only some these being mapped over to another value.